In Predictive Marketing the term ‘clustering’ gets thrown around quite a lot. It’s the predictive marketing version of segmenting. Instead of grouping people, clustering simply identifies what people do most of the time. This allows us to predict what customers are likely to do without boxing them into rigid groups.
Segmenting is the process of putting customers into groups based on similarities, and clustering is the process of finding similarities in customers so that they can be grouped, and therefore segmented. They seem quite similar, but they are not quite the same.
Confused? Let me elaborate.
Segmentation
When you segment you know who to target. If I’m selling an expensive little black dress, I want to target women who have a high annual household income. In this case I’m defining the limits of the group. Women. With annual incomes over a hundred thousand dollars who have purchased similar items in that product category. It’s natural to assume that this group of women would (be able to) buy my store’s dresses.

Identifying and grouping customers who are women and have a high income is the process of segmentation. This is important because people outside this segment most likely wouldn’t want a thousand dollar dress. Customizing my marketing for this segment makes sense.

But the segment is still quite large, and not everyone buys that dress. What if I add one more dimension to increase specificity? Age. From my data I see that women start buying designer dresses starting after twenty-one years old. (My fictional analyst says that’s when college seniors start interviewing for jobs.) So to refine my segment, I remove women under 21. But still, not everyone in this newly refined segment buys that dress. What about location? I find that only women older than 21 on the East Coast are buying that dress. Let’s remove women who are not from the East Coast. The idea is to refine the segment till you can get to a segment of one –the holy grail of marketing. But how many characteristics can a marketer refine?
If you don’t have types of data like age, income, address, or gender, AgilOne can help you get it.
With the democratization of big data, marketers now have hundreds of other characteristics they can look at. Brand preference, discount preference, only buys dresses, time spent on site, browsing behavior, length of call, etc. Some customer characteristics have no correlation to the buying behavior, while other characteristics are correlated to the buying behavior and each other in different ways. It’s just not feasible for a person to go through hundreds of types of data, finding relationships between each.
That’s when you use clustering.
Clustering
Clustering is the process of using machine learning and algorithms to identify how different types of data are related and creating new segments based on those relationships. Clustering finds the relationship between data points so they can be segmented.
In the following mockup of a cluster model for my black dress customers we see that many of the women purchased a dress in the first two months of the year and were in their early twenties (My fictional analyst couldn’t figure out the why. I’m very disappointed.)
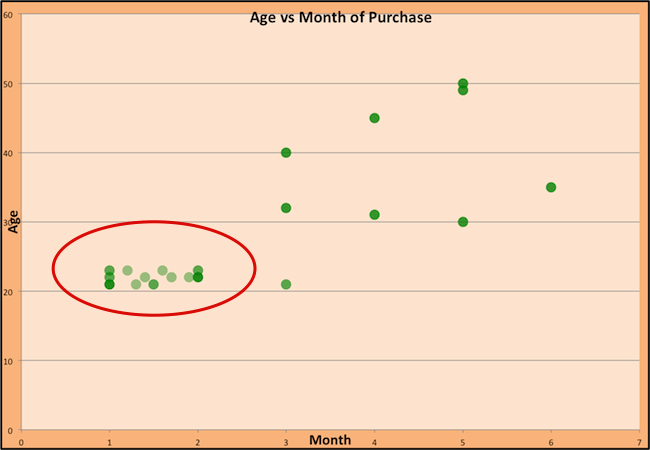
Clustering the data helped me discover a new segment of customers and their buying behaviour. AgilOne applies clustering models and hundreds of others like these to hundreds of data sets to predict a customers likelihood to buy. This is Big Data!